Wykresy punktowe, scatterplot
Stosowanie wykresów punktowych
Pojęcie “wykres punktowy” lub “scateterplot” (słowo coraz częściej używane w języku polskim) oznacza, że pewne dane zostały zaznaczone na wykresie w postaci punktowych znaczników – kółeczek, kwadracików, trójkątów, kresek lub innych wzorów, a także, choć rzadko liter lub cyferek. W taki sposób wykreśla się dane, gdy nie ma powodu by łączyć je kreskami. Najczęściej wykresami punktowymi obrazuje się zależność między dwoma zmiennymi liczbowymi. Bardzo często obiekty podlegają więcej niż dwóm pomiarom i odpowiedni “wykres” punktowy istnieje w przestrzeni wielowymiarowej. Dla trzywymiarowych wykresów można utworzyć wykres przestrzenny i wykonać jego rzut na płaszczyznę dwuwymiarową. Dla wielowymiarowych danych coraz częściej w literaturze biologicznej pojawiają się biploty – wykresy na których poszczególne zmienne zaznaczone są strzałkami, a obiekty punktami, których współrzędne nic nie znaczą (ważne jest ich rozmieszczenie względem strzałek). Ich tworzenie, interpretacja i ogólnie “czytanie” wymaga dość zmatematyzowanej teorii i zostaną one omówione później.
Gdy mamy dwa pomiary tego samego obiektu wykonanego dla dużej liczby osobników i chcemy wykonać rozrzut punktów na odpowiednim wykresie, należy dobrze zastanowić się, którą zmienną umieścimy na osi 0X, a którą na osi 0Y. Oznacza przemyślenie następującego problemu: czy zmienna pierwsza wpływa na drugą czy raczej druga na pierwszą. Mówimy tu o wpływie rozumianym jako istnienie jakichkolwiek procesów biofizycznych lub biochemicznych, które kształtowałyby w jakiś sposób wartości jednej zmiennej przy zmianach wartości drugiej zmiennej. Mówimy o zależności przyczynowo-skutkowej zmiennych od siebie.
Gdy możemy wyróżnić zmienną niezależną i zależną (a często wcale nie jest to trudne) to wartości zmiennej niezależnej umieszcza na osi poziomej, a wartości zmiennej zależnej na osi pionowej. Istnieją jednak w biologii zmienne, które bezpośrednio na siebie nie wpływają, ale ich wartości mogą zależeć od innej, nie badanej z różnych powodów, zmiennej. Wtedy w zasadzie wszystko jedno którą zmienną umieścimy na osi poziomej, a którą na osi pionowej. Zasady te obrazuje poniższy diagram:

W biologii nie ma zmiennych, które zupełnie, ani bezpośrednio ani pośrednio, niezależą od siebie. Tylko czasem ta zależność jest bardzo pośrednia i tak nikła, że można ją pominąć. Zależność i niezależność zmiennych omawiana na statystyce oznacza inne, czysto matematyczne zjawisko i tylko przez przypadek nazywa się ją tym samym słowem. Ta statystyczna zależność nie ma żadnego znaczenia, jeżli chodzi o umiejscawianie zmiennych na wykresie.
Czas przeprowadzenia badań terenowych będzie na osi 0X, a liczebność populacji w tym czasie na osi 0Y. Przy odwrotnym układzie sugerowalibyśmy, że liczebność populacji wpływa na upływ czasu. Czas jest zawsze zmienną niezależną dla wszelkich pomiarów, które zmieniają się w czasie, choć nazwanie tu zależności przyczynowo-skutkowej może być problematyczne (pewnie ze względu na jej oczywistość). Ale czy cokolwiek, co mierzymy w biologii wpływa na upływ czasu? Na ogół zmiennymi niezależnymi są wszelkie czynniki abiotyczne, jak: temperatura powietrza, wilgotność, długość dnia, odległość od szosy itd. a zależnymi wszelkie pomiary biotopu. Podobnie stężenie ołowiu w osadach dennych w różnych fragmentach jeziora będzie na osi 0X, a stężenie ołowiu w planktonie pobranym z tych fragmentów na osi 0Y. Tu już zależność nie jest na 100% oczywista, bo to obumierający plankton mógłby zanieczyszczać osady. Nie mniej, wymagałoby podtruwania planktonu z pominięciem zatruwania abiotycznych elementów jeziora, a to raczej się nie zdarza.
Bywa jednak że wyznaczenie zmiennej niezależnej i zależnej nie jest możliwe. Czy wzrost wpływa na ciężar, czy ciężar na wzrost? Obie zmienne kształtują się w okresie wzrostu osobników przez te same czynniki. Podobnie stężenia wielu zanieczyszczeń we krwi (wątrobie, nerkach, tłuszczu itd…) różnych organizmów tworzą dane, dla których bezpośredni wpływ na siebie raczej nie istnieje. Zależą one od tego, z jak bardzo zanieczyszczonego środowiska pochodzą organizmy, a z reguły środowiska zanieczyszczone są wieloma toksykantami jednocześnie.
Rozprawa o parkach narodowych w Polsce
W rozprawie o okresach politycznych w dziejach Polski najbardziej sprzyjających ochronie przyrody autor chce zamieścić wykres pokazujący zależność między czasem powstania parku narodowego, a jego powierzchnią. Dane do tego wykresu pobrał z Wikipedii.
Nazwa |
Rok powstania |
Powierzchnia [km2] |
Liczba odwiedzających rocznie |
Babiogórski Park Narodowy |
1954 |
33.9 |
60000 |
Białowieski Park Narodowy |
1932 |
105.17 |
140000 |
Biebrzański Park Narodowy |
1993 |
592.23 |
54000 |
Bieszczadzki Park Narodowy |
1973 |
291.96 |
200000 |
Park Narodowy Bory Tucholskie |
1996 |
46.13 |
60000 |
Drawieński Park Narodowy |
1990 |
113.42 |
25000 |
Gorczański Park Narodowy |
1981 |
70.3 |
45000 |
Park Narodowy Gór Stołowych |
1993 |
63.4 |
360000 |
Kampinoski Park Narodowy |
1959 |
385.48 |
1000000 |
Karkonoski Park Narodowy |
1959 |
55.8 |
2000000 |
Magurski Park Narodowy |
1995 |
194.39 |
40000 |
Narwiański Park Narodowy |
1996 |
68.1 |
5000 |
Ojcowski Park Narodowy |
1956 |
21.46 |
400000 |
Pieniński Park Narodowy |
1932 |
23.46 |
585000 |
Poleski Park Narodowy |
1990 |
97.62 |
9000 |
Roztoczański Park Narodowy |
1974 |
84.82 |
100000 |
Słowiński Park Narodowy |
1967 |
215.72 |
282000 |
Świętokrzyski Park Narodowy |
1950 |
76.26 |
400000 |
Tatrzański Park Narodowy |
1954 |
211.87 |
2500000 |
Park Narodowy Ujście Warty |
2001 |
80.74 |
10000 |
Wielkopolski Park Narodowy |
1957 |
75.83 |
? |
Wigierski Park Narodowy |
1989 |
149.99 |
120000 |
Woliński Park Narodowy |
1960 |
109.37 |
1500000 |
Odpowiednie dane łatwo z tabeli przenieść do skryptu w postaci dwóch ciągów:
x=c(1954, 1932, 1993, 1973, 1996, 1990, 1981, 1993, 1959, 1959, 1995, 1996, 1956,
1932, 1990, 1974, 1967, 1950, 1954, 2001, 1957, 1989, 1960)
y=c(33.9, 105.17, 592.23, 291.96, 46.13, 113.42, 70.3, 63.4, 385.48, 55.8,
194.39, 68.1, 21.46, 23.46, 97.62, 84.82, 215.72, 76.26, 211.87, 80.74,
75.83, 149.99, 109.37)
#
windows(4.5, 2.5)
par(mar=c(3,3,1,1), mgp=c(1.7, 0.5, 0), xaxs="i", yaxs="i")
plot(x,y,col="green3", pch=19, xlab="Rok powstania parku narodowego",
ylab=expression("Pwierzchnia [ " * km^2 * "]"),
xlim=c(1930, 2010), ylim=c(0,600), axes=FALSE)
axis(1,at=193:210*10, labels=193:210*10)
axis(2, at=0:6*100, labels=c("0","","200","","400","","600"))
|
Utworzony wykres spełnia wszystkie oczekiwania.
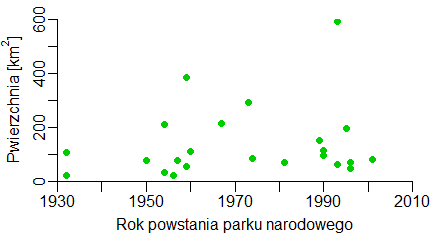
W wykresach tego typu zastosowano opcje funkcji par(): xaxs=”i” i yaxs=”i”. Powodują one, że punkt przecięcia się osi wypada zawsze w (xlim[1],ylim[1]). Należy jednak wtedy pamiętać o opcjach xlim i ylim funkcji plot(), by pole kreślenia nie zaczynało się dla najmniejszych wartości ciągów x i y, a kończyło dla największych.
Liczba turystów odwiedzających rocznie dany park pokazuje jego społeczno-edukacyjną rolę, a jednocześnie pewne zagrożenie dla chronionej przyrody zwłaszcza gdy park ma małą powierzchnię. Liczba ta wydaje się nie mieć żadnego związku z rokiem założenia parku oraz z jego powierzchnią. Można to uwidocznić na wykresie pokazującym, jak liczba odwiedzających park narodowy zależy od roku jego założenia, w którym kółeczko oznaczające zależność będzie miało powierzchnię proporcjonalną do powierzchni parku narodowego.
x=c(1954, 1932, 1993, 1973, 1996, 1990, 1981, 1993, 1959, 1959, 1995, 1996, 1956,
1932, 1990, 1974, 1967, 1950, 1954, 2001, 1957, 1989, 1960)
y=c(33.9, 105.17, 592.23, 291.96, 46.13, 113.42, 70.3, 63.4, 385.48, 55.8,
194.39, 68.1, 21.46, 23.46, 97.62, 84.82, 215.72, 76.26, 211.87, 80.74, 75.83,
149.99, 109.37)
z=c(60000, 140000, 54000, 200000, 60000, 25000, 45000, 360000, 1000000,
2000000, 40000, 5000, 400000, 585000, 9000, 100000, 282000, 400000,
2500000, 10000, NA, 120000, 1500000)
#
windows(4.5, 2.5)
par(mar=c(3,4,1,1), mgp=c(1.7, 0.5, 0), xaxs="i", yaxs="i")
plot(x,z,col="green3", pch=19, cex=sqrt(y/50),
xlab="Rok powstania parku narodowego",
ylab="Liczba odwiedzających \n [tys/rok]",
xlim=c(1930, 2010), ylim=c(0,2600000), axes=FALSE)
axis(1,at=193:210*10, labels=193:210*10)
axis(2, at=0:5*500000, labels=c("0","","1000","","2000",""))
|
Powyższy kod spowodował utworzenie wykresu:
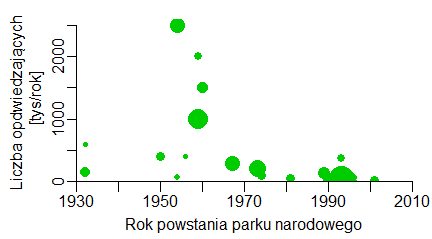
Opcja cex=c() wykorzystana do zróżnicowania wielkości znaczników, określa średnicę wykreślanego “punktu”. Aby powierzchnia znaczników była proporcjonalna do ciągu x należy pod cex= wstawić pierwiastki wartości tego ciągu.
Praca o polichlorowanych bifenylach w wątrobach dorszy z Zatoki Gdańskiej
W wątrobie dorszy złowionych w 2011 roku w Zatoce Gdańskiej oznaczono stężenia różnych pochodnych kongenerów PCB, odmian HCH (α-HCH+β-HCH+γ-HCH) i DDT (DDD+DDE+DDT). Powstała baza danych, którą można wsadzić do R i zobrazować różne zależności między zmiennymi.
dorsze = data.frame( wiek=c("5+","5+","5+","5+","5+","5+","5+","5+","5+","5+",
"5+", "5+","6+","6+","6+","6+","6+","6+","6+","6+","6+","6+","6+","6+",
"6+","6+","6+","6+","6+","6+","6+","6+","6+","6+","6+","6+","6+",
"6+","6+","6+","7+","7+","7+","7+","7+","7+","7+","7+","7+","7+",
"7+"),
PCBs=c(20.00, 20.00, 20.00, 10.00, 25.00, 25.00, 25.00, 10.00,
25.00, 25.00, 25.00, 10.00, 10.00, 30.00, 35.00, 40.00, 40.00,
40.00, 40.00, 45.00, 35.00, 35.00, 10.00, 45.00, 40.00, 40.00,
40.00, 40.00, 55.00, 55.00, 55.00, 60.00, 60.00, 60.00, 50.00,
40.00, 50.00, 60.00, 60.00, 60.00, 80.00, 80.00, 90.00, 90.00,
100.00, 150.00, 200.00, 200.00, 150.00, 100.00, 200.00),
HCH=c(15.00, 15.00, 10.00, 10.00, 0.00, 5.00, 15.00, 30.00, 25.00,
10.00, 25.00, 30.00, 35.00, 35.00, 35.00, 35.00, 40.00, 35.00,
35.00, 40.00, 45.00, 45.00, 45.00, 45.00, 40.00, 35.00, 35.00,
40.00, 50.00, 60.00, 60.00, 80.00, 50.00, 40.00, 60.00, 40.00,
60.00, 80.00, 40.00, 70.00, 100.00, 80.00, 130.00, 70.00, 135.00,
70.00, 135.00, 90.00, 85.00, 65.00, 70.00),
DDT = c(35.00, 35.00, 10.00, 10.00, 10.00, 30.00, 35.00, 45.00,
10.00, 20.00, 40.00, 45.00, 60.00, 70.00, 50.00, 60.00, 60.00,
45.00, 45.00, 45.00, 70.00, 70.00, 70.00, 45.00, 70.00, 70.00,
75.00, 75.00, 95.00, 105.00, 55.00, 90.00, 100.00, 95.00, 50.00,
80.00, 105.00, 105.00, 60.00, 80.00, 115.00, 90.00, 90.00, 70.00,
110.00, 80.00, 155.00, 90.00, 160.00, 50.00, 100.00))
|
W pierwszej kolumnie wpisano przybliżoną wartość wieku złowionych dorszy określoną po ich wymiarach.
Chcąc zobrazować wzajemne związki między tymi trzema zmiennymi (czy wzrost stężenia PCBs wiąże się z większymi wartościami HCH i DDT) można wykonać trzy wykresy typu plot(). Aby zaznaczyć różnymi kolorami wiek badanych dorszy zdefiniowano funkcję kol().
kol = function(x){y=1:length(x)
for (i in 1:length(x)){ if (x[i]=="5+") y[i]="green"
if (x[i]=="6+") y[i]="blue"
if (x[i]=="7+") y[i]="red"}
y}
#
windows(2.5, 2.5)
par(mar=c(2.7,2.7,0.5,0.5), mgp=c(1.5,0.5,0))
plot(dorsze$PCBs,dorsze$HCH, pch=19,xlab="PCBs",
ylab="HCH", col=kol(dorsze$wiek))
#
windows(2.5, 2.5)
par(mar=c(2.7,2.7,0.5,0.5), mgp=c(1.5,0.5,0))
plot(dorsze$PCBs,dorsze$DDT, pch=19,xlab="PCBs",
ylab="DDT", col=kol(dorsze$wiek))
#
windows(2.5, 2.5)
par(mar=c(2.7,2.7,0.5,0.5), mgp=c(1.5,0.5,0))
plot(dorsze$HCH,dorsze$DDT, pch=19,xlab="HCH",
ylab="DDT", col=kol(dorsze$wiek))
|
Powstaną w ten sposób następujące wykresy:
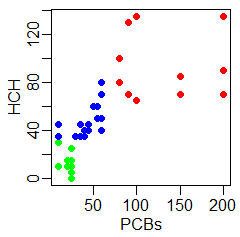
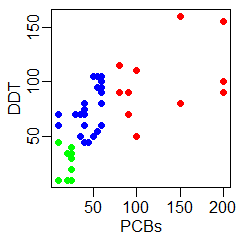
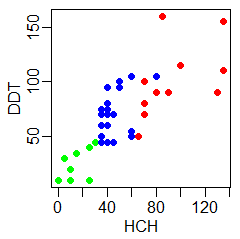
Można jeszcze uznać za stosowne narysowanie zależności PCBs od HCH, PCBs od DDT i HCH od DDT, gdyż tego typu dane nie określają zmiennej zależnej i niezależnej. Powstałe wykresy byłyby odbiciem symetrycznym względem przekątnej uzyskanych wcześniej wykresów. Często w takich przypadkach tworzy się macierz wykresów, którą w R można wykonać za pomocą funkcji pairs(). Funkcja ta nie korzysta z opcji graficznych opisanych funkcją par(), ale posiada wiele własnych opcji graficznych regulujących szerokość marginesów wewnętrznych i zewnętrznych, wielkość czcionek itp. Można o nich przeczytać po wywołaniu pomocy ?pairs.
windows(5, 5) pairs(~PCBs+HCH+DDT,data=dorsze, col=kol(dorsze$wiek), pch=19, main="Macierz wzajemnych zależności między zmiennymi", oma=c(2,2,5,2)) |
Macierz ta wygląda następująco:
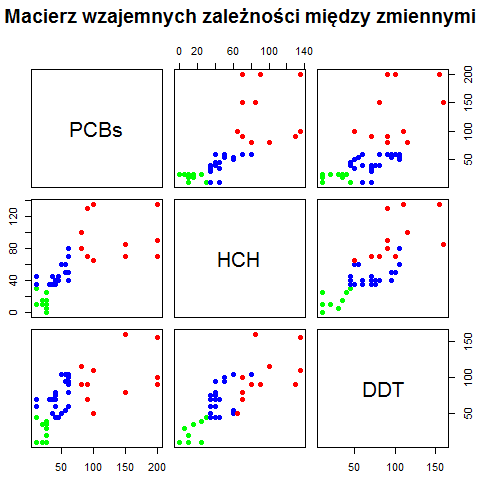
Niekiedy istnieje potrzeba zobrazowania wszystkich tych zależności na jednym trzywymiarowym wykresie. W standardowych pakietach takich możliwości nie ma. Najbardziej przejrzyste wykresy punktowe trójwymiarowe znajdują sią, jak dotąd, w pakiecie scatterplot3d. Trzeba go najpierw zainstalować. Należy wybrać z górnego menu opcje “Pakiety”, następnie “Zainstaluj pakiety” i po wybraniu kraju z serwerem CRAN wybrać pakiet scatterplot3d. Następnie można uruchomić program:
windows(4, 4) library(scatterplot3d) scatterplot3d(dorsze$PCBs,dorsze$HCH,dorsze$DDT, xlab="PCBs", ylab="HCH", zlab="DDT", main="Wzajemne związki między zmiennymi") # windows(4, 4) library(scatterplot3d) scatterplot3d(dorsze$PCBs,dorsze$HCH,dorsze$DDT, xlab="PCBs", ylab="HCH", zlab="DDT", type="h", pch=19, color=kol(dorsze$wiek), main="Wzajemne związki między zmiennymi") |
Drugi wykres jest taki sam jak pierwszy, tylko po zastosowaniu odpowiednich opcji w funkcji scatterplot3d(). Funkcja ta bowiem nie korzysta z opcji graficznych funkcji par().
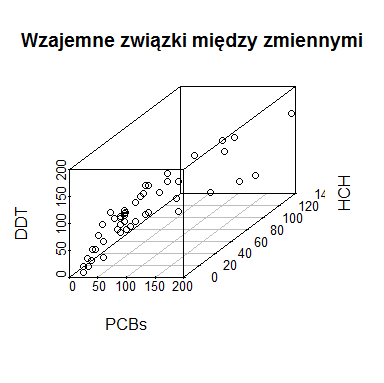
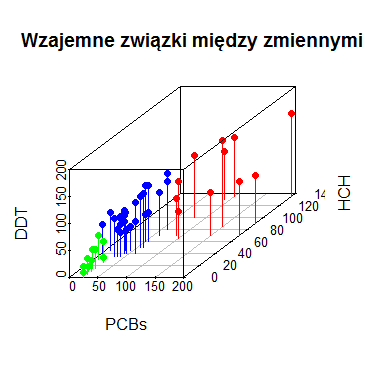
Funkcja scatterplot3d(x,y,z) ma bardzo dużo opcji, między innymi:
- color – ciag kolorów poszczególnych punktów,
- main, sub – tytuł i podtytuł wykresu,
- xlim, ylim, zlim – zakresy wartości poszczególnych zmiennych,
- xlab, ylab, zlab – nazwy poszczególnych zmiennych,
- scale.y – skala dla zmiennej y względem zmiennych x i z
- angle – kąt miedzy zmiennymi x i y
- axis – zmienna logiczna pokazująca czy osie mają być rysowane przez funkcje scatterplot3d,
- tick.marks – zmienna logiczna wskazująca czy mają być rysowane domyślne znaczniki na osiach,
- grid – zmienna logiczna wskazująca czy na płaszczyźnie x×y ma zostać narysowana siatka,
- box – zmienna logiczna wskazująca, czy ma zostać zaznaczone pudełko, w którym zamknięte są dane,
- type – jeden ze znaków “p” (punkty), “l” (linie), “h” (pionowe odcinki) oznaczający sposób zobrazowania punktów (x,y,z),
- highlight.3d – zmienna logiczna, której wartość TRUE powoduje zróżnicowanie kolorów różnych punktów w zależności od wartości zmiennej z,
- col.axis, col.grid, col.lab – kolory osi, siatki, podpisów,
- cex.symbols, cex.axis, cex.lab – rozmiary punktów, znaczników osi, czcionki,
- font.axis, font.lab – czcionki użyte na wykresie,
- lty.axis, lty.grid, lty.hplot – typy linii użytych do wykreślenia osi, siatki, pionowych linii łączących punkty z płaszczyzną x×y.
Pozostałe opcje można znaleźć w pliku pomocy, który zostanie wgrany po wywołaniu ?scatterplot3d.